
Usage data is one of the main engines of modern businesses, enabling them to bill customers based on consumption, identify sales opportunities and customer health, and predict revenue. Given these critical applications, it's clear that accuracy is a must. No one wants to undercharge or overcharge a customer or make a business decision based on inaccurate data. Engineers are tasked with balancing consistency, latency, and cost trade-offs to deliver real-time, accurate data that powers business use cases.
This is especially challenging if you need to meter usage in a distributed system where services communicate on an unreliable network with retries or workloads continuously scaling up and down, and you need to ensure the usage data is scraped or reported before the producer workload gets decommissioned. In this continuously changing system, we must ensure that usage is metered once and exactly once to maintain accuracy. The standard solution to handle unreliable networks is to retry; it’s better to report a usage twice and filter out duplicates later than to underreport it. But deduplication is where things get tricky. Dedicating large volumes of data and servicing accurate aggregated meters in real time requires some preparation. In this article, we will discuss what deduplication solutions the OpenMeter team considered and what tradeoffs they came with.
Defining Usage Idempotency
Idempotency refers to the property of an operation where no matter how many times you process the same event, it always gives you the same result: the event is counted only once towards the meter. To achieve idempotency in usage metering, we need to establish the criteria for identifying when an event is unique:
When is an event unique?
Determining the uniqueness of an event involves assigning a unique idempotency key. This key, typically generated by the client, contains random and time components. You can often leverage existing idempotent keys, such as a request or third-party API call IDs, within your usage metering business logic. It is also a good idea to include source information if you collect usage from many parallel processes to reduce the chance of hash collision. Here are a couple of common idempotency key examples from the industry:
- Request id:
X-Request-ID: pIqXbKDuhr0QXYLi - UUID:
uuidV4()=>32f481bf-1965-43fa-9053-14941534afd1 - CloudEvents:
{ "id": "1234", "source": "my-hostname" ... } - Log entry:
timestamp=1689963678359, host="i-a234rc", message="hello world"
How long do we consider an event to be unique?
Uniqueness has a time component that defines the window within which an event is considered unique based on the idempotency key. This time window ensures that even if you need to replay usage events for a specific period, they are still treated as unique and avoid duplication. This is necessary so you don’t need to store the idempotency key indefinitely on your backend.
When to deduplicate and how?
This section will explore where you want to deduplicate usage data in your processing and metering pipeline, with some example solutions. Each comes with its own consistency, duration, and latency trade-offs. Sometimes, you can combine them based on your use case to achieve the best of multiple worlds.
1. In collection time at the usage source
In distributed systems, with multiple instances producing data parallel, it's challenging to deduplicate usage at collection time efficiently, deduplication would need to be stateful and look for idempotency across multiple processes. As collectors are primarily stateless, deduplication over a longer window or across multiple processes is heavily limited. If you use a centralized collector in your system, deduplication can be possible before sending usage to the metering system as it sees the system holistically until it's only one instance. Although even with centralized collectors, if they are stateless, the deduplication window will be small, relying on historical idempotency keys stored in memory since the last restart. Guaranteeing deduplication in such a system is not feasible; it's all best effort.
A popular solution for centralized collectors is the open-source
Vector by DataDog, which comes with a built-in
buffer-based deduplication component. In Vector’s dedupe component, you can
define one or multiple fields as your idempotency key and the number of events
that should be kept in the buffer. Vector will look back in this buffer to
determine if new events should be dropped or forwarded to the metering system.
This can be efficient around network retries in distributed systems as most
retries have relatively small time windows, but we can’t guarantee consistency
as we don’t know how quickly the historical buffer fills up under the current
traffic and drops old events.
2. At Ingestion Time in the Metering System
Deduplicating at ingestion time before we write data to long-term storage is the most powerful option, as we can filter out duplicates across multiple sources and use states to store historical idempotency keys on a longer time window. This can happen in the ingestion pipeline, or the storage engine. Let’s discuss our options here through a few examples:
2.1. In the Processing Pipeline via Bloom Filters
Using probabilistic data structures like Bloom Filter is a common way to deduplicate events in messaging queues like Kafka. Bloom filters enable you to check if an element is present in a set using a small memory space of a fixed size. They do this efficiently by only storing the hash of an event, sacrificing some precision. This means we will have hash collisions, sometimes leading to false positives and dropped events, called error rates. We can control the bloom filter’s error rate by defining the storage size for our hashes. Although the bloom filter can drop events with a tiny error rate, it’s probably a better choice for billing than double-counting an event. Bloom filters are implemented in some Key-Value databases like Redis, so you can implement the deduplication in your event ingestion pipeline before writing records to the database.
2.2. In Kafka via Stream Processing
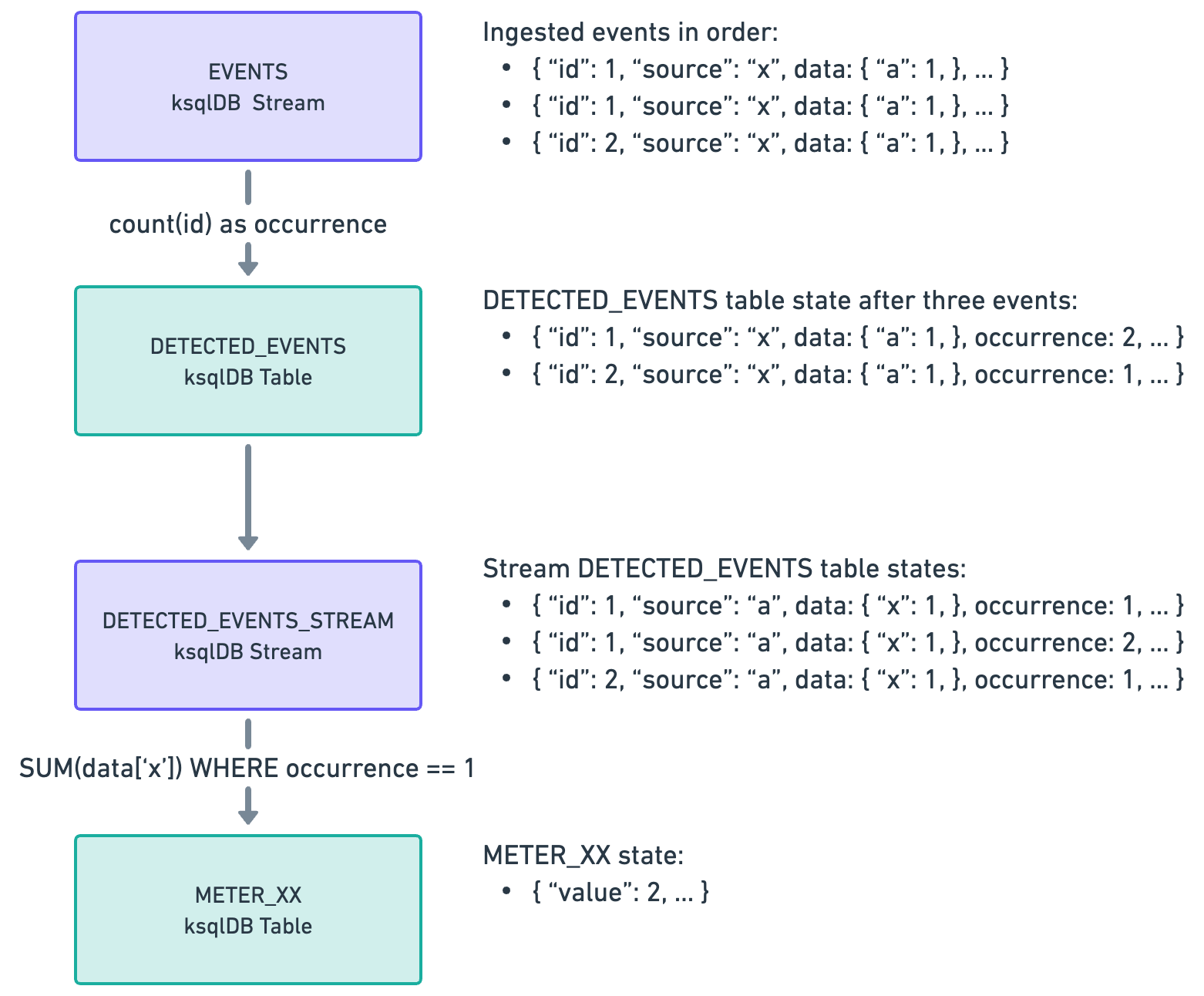
To guarantee high consistency, you can deduplicate events in stream processing. As you ingest events into a Kafka topic, you can use a stream processor like ksqlDB or Arroyo to consume events from this topic and count their occurrences using the idempotency key. As events come in, you only push events at their first occurrence to the next step, usually an another Kafka topic for aggregation and long-term storage.
2.3. In a Database by Storage Engine
In traditional databases, you can use primary keys to upsert existing data or
drop duplicates. But such guarantees don’t scale when inserting larger volumes
of data for usage metering. This is why databases designed for large volumes of
real-time analytics, like ClickHouse, have built-in
solutions to handle duplicates. For example, when executing an internal
optimization job, the ReplacingMergeTree table engine cancels out duplicates
over time. The challenge is that there are no guarantees when such optimization
runs in the system, so those duplicates can be present for hours or longer,
causing eventual consistency and unexpected aggregated results, leading to
potential double counting in billing and reports.
3. Before Serving Usage to Consumers
Filtering out duplicates at query time is the simplest. This is also usually the
most expensive, as your database must scan the whole dataset to count
occurrences and filter out data. Deduplication at query time is usually not
feasible on large data sets as it puts an extensive load on your data store and
results in slow queries. But it can be pretty efficient with aggregation
resilient to duplicates, such as MIN and MAX, where you don’t need to handle
deduplication. Deduplication at query time also means you aggregated data at
query time. Querying the raw data in real-time for online use cases in most
systems is not possible in a scalable and efficient way.
How OpenMeter deduplicates with Kafka and ksqlDB
OpenMeter, the open-source accurate usage metering solution, ingests usage data through events using the CloudEvents specification and leverages Kafka for stream processing. Let's provide a high-level overview of how deduplication works in OpenMeter.
You can also check out the corresponding technical decisions doc on GitHub.
Unique Events
OpenMeter achieves event deduplication by considering the combination of id and source. This approach aligns with the CloudEvents specification:
Producers MUST ensure that
source+idis unique for each distinct event. If a duplicate event is re-sent (e.g. due to a network error) it MAY have the sameid. Consumers MAY assume that Events with identicalsourceandidare duplicates.
An example of a typical usage event in CloudEvent format:
{
"specversion": "1.0",
"type": "api-calls",
"id": "00001",
"time": "2023-01-01T00:00:00.001Z",
"source": "service-0",
"subject": "customer-1",
"data": {
"execution_duration": "12",
"bytes_transfered": "12345",
"path": "/hello"
}
}In this case, the usage event is considered unique based on id=00001 and
source=service-0.
Deduplication
Within OpenMeter, the API server sends each event to a Kafka topic without explicitly checking for uniqueness. The deduplication process takes place during the streaming processing stage. Each event's occurrence is counted within the deduplication window, which is set to 32 days by default. Only events that occur for the first time within this window are further processed and incorporated into the metering.
The deduplication logic in OpenMeter is implemented by combining tables and streams in ksqlDB:
Summary
In this blog post, we discussed the challenges of processing usage data exactly once to avoid overcharging or undercharging customers, especially in distributed systems. Engineers can implement robust solutions that guarantee accurate usage metering by defining idempotency and understanding the criteria for unique event identification, such as unique keys and time windows. We also discussed how OpenMeter implemented idempotency and deduplication with CloudEvent, Kafka, and ksqlDB.


