How It Works
OpenMeter uses a stream processing architecture to collect usage events and turn them into metered consumption. This guide explains how OpenMeter ingests events via Kafka and transfers them into ClickHouse, the columnar database used as long-term storage.
Stream Processing Pipeline
First, the OpenMeter API accepts events in the CloudEvents format and publishes them to Kafka topics before further processing them. This allows OpenMeter to process events in batches and handle traffic spikes efficiently.
The events are then processed by a custom Kafka Consumer written in Go, which, validates events and ensures consistent deduplication and exactly-once inserts into ClickHouse. The Kafka Consumer scales horizontally by Kafka partitions, allowing for parallel processing of events and ensuring high availability.

Scaling Through Partitions
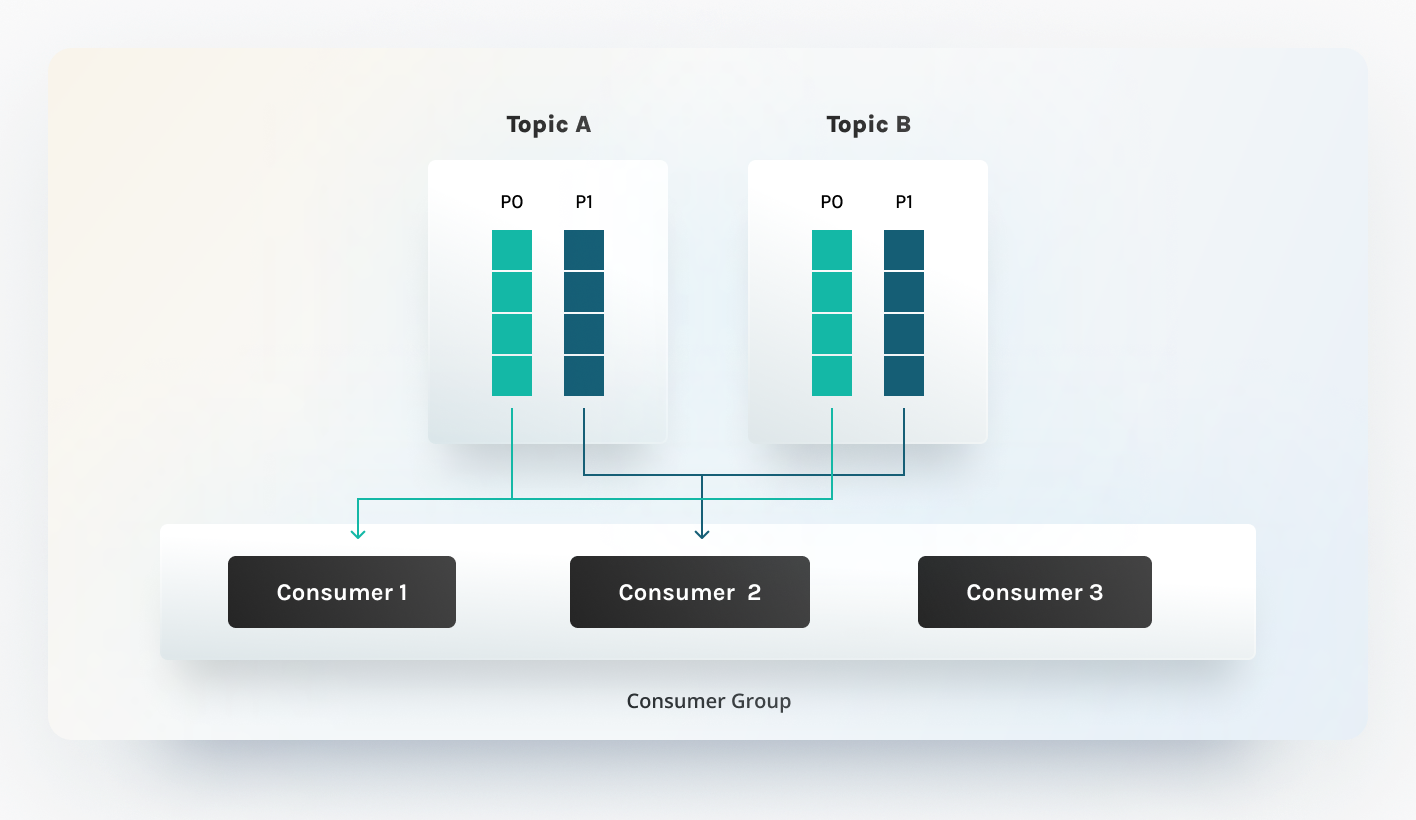
Given that Kafka scales via partitions (with a single topic backed by multiple
partitions), we adopted a similar strategy for our consumer workers. This
approach is relatively simple to implement, thanks to the inherent rebalancing
logic in Kafka clients. When clients subscribe to Kafka topics, they subscribe
to specific partitions of a topic, where the Kafka broker determines the
allocation. While various rebalancing strategies exist, we currently employ the
default RangeAssignor, which assigns consumer partitions in a lexicographic
sequence. Check out this
detailed article
to learn about Kafka partition assignments and strategies.
ClickHouse Storage
ClickHouse is a columnar database that excels at handling time-series data and is optimized for fast reads and writes. OpenMeter uses ClickHouse as a database to store consumption data.
OpenMeter Talks
Check out the following talks to learn more about OpenMeter's event ingestion pipeline:
November 2023, ClickHouse Meetup in San Francisco, CA, USA
May 2024, Cloud Native Meetup in Budapest, Hungary
Learn More
Last updated on