
While working on OpenMeter, one critical task was providing a robust solution to transfer events from Kafka to ClickHouse without duplicates. Since our customers rely on us for accurate billing, our approach had to be precise and consistent. This article chronicles our journey, from our initial use of Kafka Connect to eventually building our own Kafka consumer designed for increased consistency and reliability.
Starting with ksqlDB and Kafka Connect
In July 2023, when we launched OpenMeter on GitHub, ksqlDB was our initial choice to deduplicate and aggregate usage events. Given that ksqlDB stores states in Kafka topics, it was a straightforward decision to leverage Kafka Connect, which provides a consistent pipeline for moving large data sets in and out of Kafka.
Kafka Connect also supports various source and sink connector plugins, including databases like ClickHouse, PostgreSQL, and MongoDB. It also excels in breaking a single job into multiple smaller tasks, optimizing parallelism and load distribution.
In an earlier blog post, we discussed implementing consistent deduplication with ksqlDB. KsqlDB produced unique events into Kafka topics, which then we sank to PostgreSQL via the JDBC Kafka Connect plugin, which allowed upserts based on PG primary keys. This worked well, but we eventually moved away from this stack as we ran into scaling challenges with ksqlDB.
Transitioning to ClickHouse and Kafka Connect
As we switched to ClickHouse for a more scalable aggregation and long-term storage, we needed to rework our deduplication. Temporarily, we started to check for duplicates in the API layer with Redis, but this wasn’t great for consistency, as parallel requests can lead to double-counting usage. With ClickHouse, we continued to use Kafka Connect as the ClickHouse team built a robust sink plugin that implements exactly-once delivery and can insert events in batches, which is important to scale with ClickHouse.

Exactly once processing is critical, as Kafka Connect tasks are only aware of the latest topic offset acknowledged by the consumer.
For example, consumers can fail to acknowledge a processed offset due to a network error or an exception. The exactly-once guarantee prevents double-inserting usage, leading to incorrect billing. You can delve deeper into the ClickHouse Kafka Connect Sink design on their GitHub.
While the ClickHouse Kafka Connect Sink excelled at safely scaling batch insertions, we faced new hurdles. Invalid events could cause an entire batch to fail, redirecting events into a dead-letter queue for subsequent processing. This necessitated reconciling failed messages and generally slowed down our event processing.
With already wanting to move dedupe logic out of the API and being keen to reduce the impact of invalid events during processing, we felt that a more custom-tailored solution is needed.
Building our Go Kafka Consumer
Informed by our previous challenges and learnings around deduplication and batch processing, we aspired to design a Kafka Consumer that would:
- Ensure consistent deduplication.
- Guarantee exactly-once inserts into ClickHouse.
- Processes events in batches.
- Validate events against meters.
- Redirect invalid events to a dead letter queue.
- Scales horizontally by partitions.
Let’s discuss how we met these requirements and built our Kafka consumer workers using Go.

Deduplication and Exactly-Once Guarantees
In our context, Deduplication goes hand in hand with the exactly-once guarantee. Through deduplication, we prevent redundant event insertions. We realized that whether duplicates originate from customer applications reporting recurrent events or from our Kafka consumer reprocessing a message due to network issues, we can rely on the same deduplication logic.
Scaling Through Partitions
Given that Kafka scales via partitions (with a single topic backed by multiple
partitions), we adopted a similar strategy for our consumer workers. This
approach is relatively simple to implement, thanks to the inherent rebalancing
logic in Kafka clients. When clients subscribe to Kafka topics, they subscribe
to specific partitions of a topic, where the Kafka broker determines the
allocation. While various rebalancing strategies exist, we currently employ the
default RangeAssignor, which assigns consumer partitions in a lexicographic
sequence. Check out this
detailed article
to learn about Kafka partition assignments and strategies.
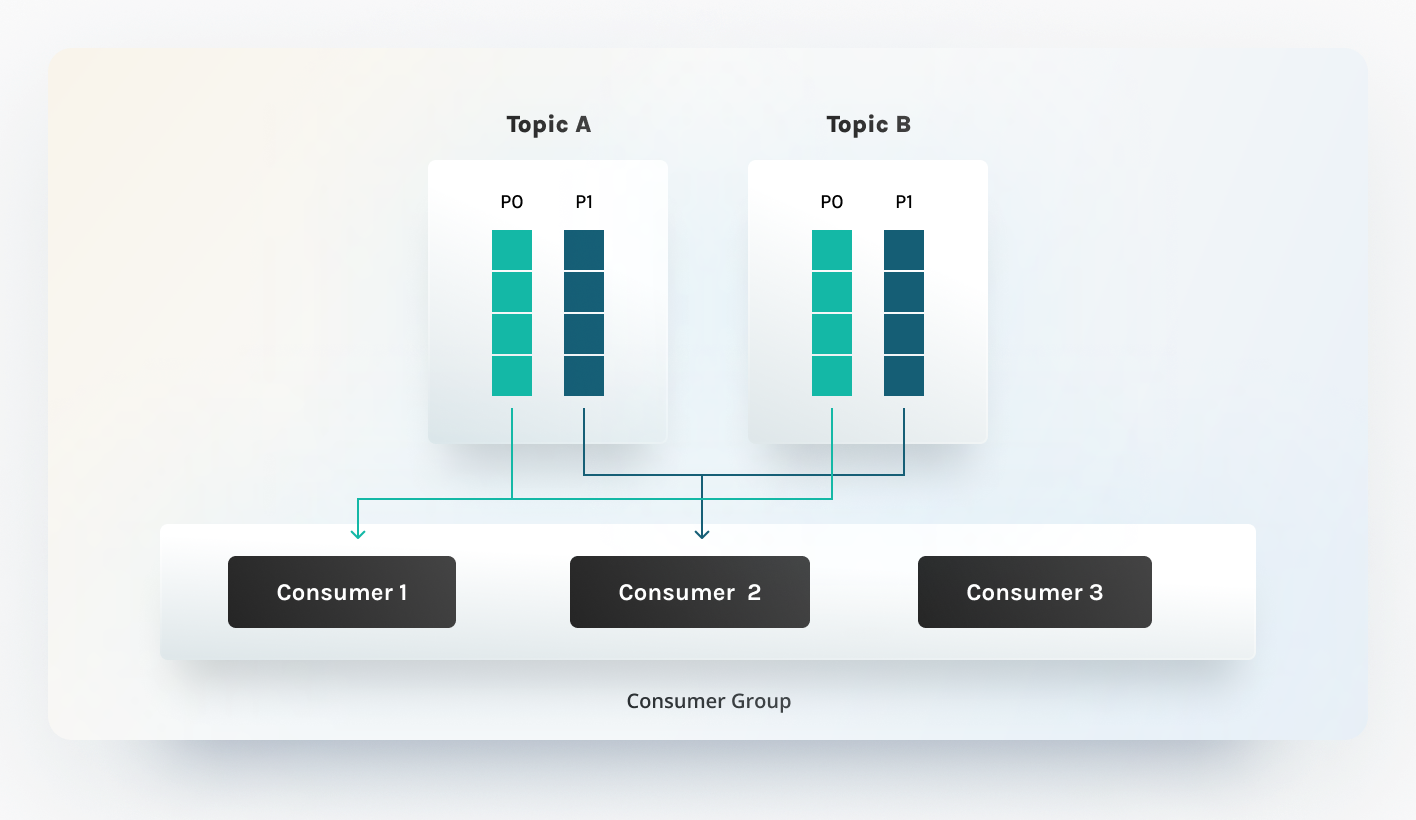
Idempotent Processing
Scaling, consumers per partition, also means we only need to ensure consistency on a partition level until events with the same idempotency key end up in the same partition, which we can ensure by setting the Kafka message key. By processing partitions sequentially in batches and deduping inside the batch in memory, we can apply the following framework to ensure consistency:
- Poll events from Kafka based on the latest consumer offset.
- Filter and discard invalid events.
- Eliminate in-batch duplicates.
- Filter out duplicates using Redis.
- Sink events to ClickHouse.
- Set event keys in Redis
- Commit the new consumer offset to Kafka.
When any of these steps fail due to network issues, we reprocess the entire batch from the beginning. This is viable as our processing steps are idempotent, provided at least one of the offset commits to Kafka or Redis set is successful. On the rare occasions when both Kafka and Redis are operational for the initial five steps but fail during the last two (despite multiple retries), manual reconciliation is required.
Validation Before Inserts
We also introduced event validation and dead lettering part of our consumer, marking a significant enhancement over our prior Kafka Connect-driven architecture. To manage vast data volumes, we insert data into ClickHouse in larger batches. It is important to have only valid rows in an insert statement, as any malformed event can make the entire batch fail. Previously, we had to reconcile batches to filter out invalid events. With our revamped consumer, every event is validated against its respective meters before being sent to ClickHouse. This accelerates our processing and routes invalid events to a specialized dead letter queue for manual inspection.
Implemented in Go
On the operational side, we also felt limited with Kafka Connect as we had to manage plugin binary versions and couldn't extract all the metrics and logs we needed to have good visibility into our event processing. By implementing our consumer worker in Go, we can achieve a more tailored observability and double down on a single programming language across the OpenMeter project.
Summary
Throughout our journey with OpenMeter, we've continuously enhanced our Kafka event processing accuracy and consistency. We began with ksqlDB and Kafka Connect, appreciating their ability to handle vast datasets and deduplicate events. However, as our needs evolved and we transitioned to ClickHouse for better scalability, we recognized the necessity of a more tailored solution. This led us to develop our own Kafka Consumer in Go, a custom-built solution for robust deduplication, exactly-once guarantees, batch processing efficiency, and event validation. This new consumer ensures accurate billing for our customers and offers improved scalability and performance.
We are also excited to announce that the sink worker is available now in our Open Source distribution. You can find the implementation on the OpenMeter GitHub.


